Introduction
Two years ago we first announced the launch of Feast, an open source feature store for machine learning. Feast is an operational data system that solves some of the key challenges that ML teams encounter while productionizing machine learning systems.
Recognizing that ML and Feast have advanced since we launched, we take a moment today to discuss the past, present and future of Feast. We consider the more significant lessons we learned while building Feast, where we see the project heading, and why teams should consider adopting Feast as part of their operational ML stacks.
Background
Feast was developed to address the challenges faced while productionizing data for machine learning. In our original Google Cloud article, we highlighted some of these challenges, namely:
- Features aren’t reused.
- Feature definitions are inconsistent across teams.
- Getting features into production is hard.
- Feature values are inconsistent between training and serving.
Whereas an industry to solve data transformations and data-quality problems already existed, our focus for shaping Feast was to overcome operational ML hurdles that exist between data science and ML engineering. Toward that end, our initial aim was to provide:
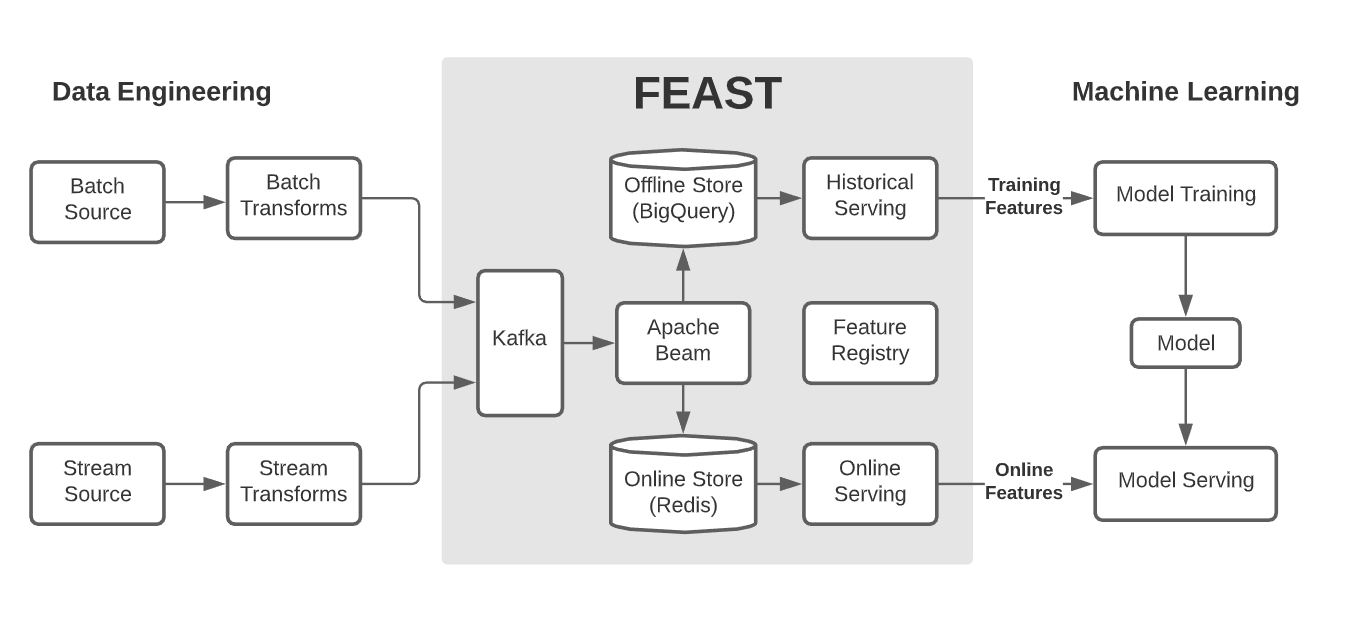
- Registry: The registry is a common catalog with which to explore, develop, collaborate on, and publish new feature definitions within and across teams. It is the central interface for all interactions with the feature store.
- Ingestion: A means for continually ingesting batch and streaming data and storing consistent copies in both an offline and online store. This layer automates most data-management work and ensures that features are always available for serving.
- Serving: A feature-retrieval interface which provides a temporally consistent view of features for both training and online serving. Serving improves iteration speed by minimizing coupling to data infrastructure, and prevents training-serving skew through consistent data access.
- Monitoring: Tools that allow operational teams to monitor and act on the quality and accuracy of data consumed by models. This is achieved through the generation of statistics, metrics, logs, alerts, and data validation.
Guided by this design, we co-developed and shipped Feast with our friends over at Google. We then open sourced the project in early 2019, and have since been running Feast in production and at scale. In our follow up blog post, Bridging ML Models and Data, we touched on the impact Feast has had at companies like Gojek.
Feast today
Teams, large and small, are increasingly searching for ways to simplify the productionization and maintenance of their ML systems at scale. Since open sourcing Feast, we’ve seen both the demand for these tools and the activity around this project soar. Working alongside our open source community, we’ve released key pieces of our stack throughout the last year, and steadily expanded Feast into a robust feature store. Highlights include:
- Point-in-time correct queries that prevent feature data leakage.
- A query optimized table-based data model in the form of feature sets.
- Storage connectors with implementations for Cassandra and Redis Cluster.
- Statistics generation and data validation through TFDV integration.
- Authentication and authorization support for SDKs and APIs.
- Diagnostic tooling through request/response logging, audit logs, and Statsd integration.

Feast has grown more rapidly than initially anticipated, with multiple large companies, including Agoda, Gojek, Farfetch, Postmates, and Zulily adopting and/or contributing to the project. We’ve also been working closely with other open source teams, and we are excited to share that Feast is now a component in Kubeflow. Over the coming months we will be enhancing this integration, making it easier for users to deploy Feast and Kubeflow together.
Lessons learned
Through frequent engagement with our community and by way of running Feast in production ourselves, we’ve learned critical lessons:
Feast requires too much infrastructure: Requiring users provision a large system is a big ask. A minimal Feast deployment requires Kafka, Zookeeper, Postgres, Redis, and multiple Feast services.
Feast lacks composability: Requiring all infrastructural components be present in order to have a functional system removes all modularity.
Ingestion is too complex: Incorporating a Kafka-based stream-first ingestion layer trivializes data consistency across stores, but the complete ingestion flow from source to sink can still mysteriously fail at multiple points.
Our technology choices hinder generalization: Leveraging technologies like BigQuery, Apache Beam on Dataflow, and Apache Kafka has allowed us to move faster in delivering functionality. However, these technologies now impede our ability to generalize to other clouds or deployment environments.
The future of Feast
“Always in motion is the future.”
– Yoda, The Empire Strikes Back
While feature stores have already become essential systems at large technology companies, we believe their widespread adoption will begin in 2021. We also foresee the release of multiple managed feature stores over the next year, as vendors seek to enter the burgeoning operational ML market.
As we’ve discussed, feature stores serve both offline and production ML needs, and therefore are primarily built by engineers for engineers. What we need, however, is a feature store that’s purpose-built for data-science workflows. Feast will move away from an infrastructure-centric approach toward a more localized experience that does just this: builds on teams’ existing data-science workflows.
The lessons we’ve learned during the preceding two years have crystallized a vision for what Feast should become: a light-weight modular feature store. One that’s easy to pick up, adds value to teams large and small, and can be progressively applied to production use cases that span multiple teams, projects, and cloud-environments. We aim to reach this by applying the following design principles:
1. Python-first: First-class support for running a minimal version of Feast entirely from a notebook, with all infrastructural dependencies becoming optional enhancements.
- Encourages quick evaluation of the software and ensures Feast is user friendly
- Minimizes the operational burden of running the system in production
- Simplifies testing, developing, and maintaining Feast
2. Production-ready: A collection of battle-tested components built for production.
- Manages high-scale operational workloads for both training and serving
- Integrates with industry-standard monitoring systems for both data and services
- Provides a simplified architecture that facilitates diagnostics and debugging
3. Composability: Modular components with clear extension, integration, and upgrade points that allow for high composability.
- Grants teams the flexibility to adopt specific Feast components
- Incentivizes defining clear component boundaries and data contracts
- Eliminates barriers on teams intending to swap in their existing technologies
4. Cloud-agnostic: Removal of all hard coupling to cloud-specific services, and inclusion of portable technologies like Apache Spark for data processing and Parquet for offline storage.
- Enables deployment into all cloud and on-premise environments
- Introduces a rich set of storage and integration options through Spark I/O
- Improves development velocity by allowing all infrastructure to run locally

Next Steps
Our vision for Feast is not only ambitious, but actionable. Our next release, Feast 0.8, is the product of collaborating with both our open source community and our friends over at Tecton.
- Python-first: We are migrating all core logic to Python, starting with training dataset retrieval and job management, providing a more responsive development experience.
- Modular ingestion: We are shifting to managing batch and streaming ingestion separately, leading to more actionable metrics, logs, and statistics and an easier to understand and operate system.
- Support for AWS: We are replacing GCP-specific technologies like Beam on Dataflow with Spark and adding native support for running Feast on AWS, our first steps toward cloud-agnosticism.
- Data-source integrations: We are introducing support for a host of new data sources (Kinesis, Kafka, S3, GCS, BigQuery) and data formats (Parquet, JSON, Avro), ensuring teams can seamlessly integrate Feast into their existing data-infrastructure.
Get involved
We’ve been inspired by the soaring community interest in and contributions to Feast. If you’re curious to learn more about our mission to build a best-in-class feature store, or are looking to build your own: Check out our resources, say hello, and get involved!
- Project website: feastsite.wpenginepowered.com
- Come and say hello to us in #Feast
- Our documentation: docs.feastsite.wpenginepowered.com
- GitHub repository: feast-dev/feast