
This post was originally published on Tecton.ai on December 22, 2022.
In the past, we’ve explored the differences between a feature store and a feature platform, how to choose between the two, and the real-time machine learning challenges they help solve. We also recently held a webinar about choosing between Feast and Tecton.
In this blog, we’ll dive deeper to explore:
- the product differences between Feast and Tecton
- how ML Engineers and data scientists use Feast and Tecton
- the main considerations for choosing between Feast and Tecton
What are Feast and Tecton?

Feast is the leading open-source, self-managed feature store, which helps engineers store and serve feature values for model training and online inference.
Tecton is the leading feature platform, delivered as a fully-managed SaaS service. Tecton includes a feature store and extends it to provide a complete end-to-end solution for data scientists, engineers, and admins to create, manage, monitor, and serve features.
Product differences between Feast and Tecton
Feast and Tecton are very different in the scope of services they provide.
Feast is a feature store, and is designed to store and serve features consistently for both training and online inference. But Feast is not a complete solution for managing features. Specifically, Feast:
- provides a simple set of APIs to push feature values consistently to offline and online stores, to generate accurate training datasets, and to serve features online.
- does not automate the transformation of raw data into feature values. Engineers still have to build and manage custom pipelines to process the raw data.
- does not provide a declarative framework to define features-as-code and collaborate on feature definitions.
- does not provide a UI to discover, share, and re-use features.
- does not provide built-in monitoring of data quality and online service levels.
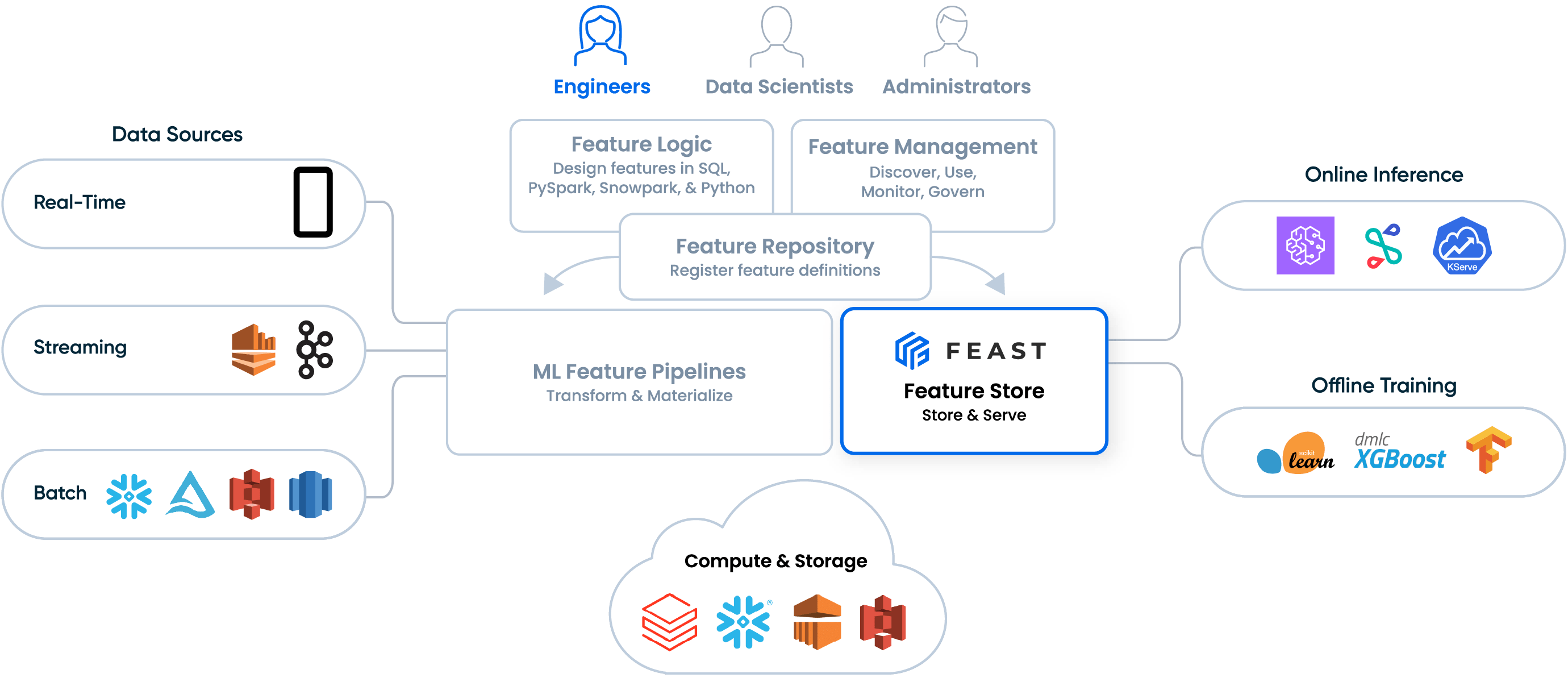
Tecton, on the other hand, is a complete feature platform. Like Feast, it includes a feature store to store and serve features for training and online inference. But Tecton also provides:
- a Feature engine to automate the transformation of raw data into fresh features values. The feature engine can orchestrate batch, streaming, and real-time transformations, and re-uses existing processing infrastructure like Spark and Snowflake to process the data.
- a declarative framework to define features-as-code, and a Git repo to manage and collaborate on feature versions using DevOps best practices.
- a central feature repo with a UI to discover, share and re-use existing features.
- monitoring of features, including data quality, data drift, and operational service levels.
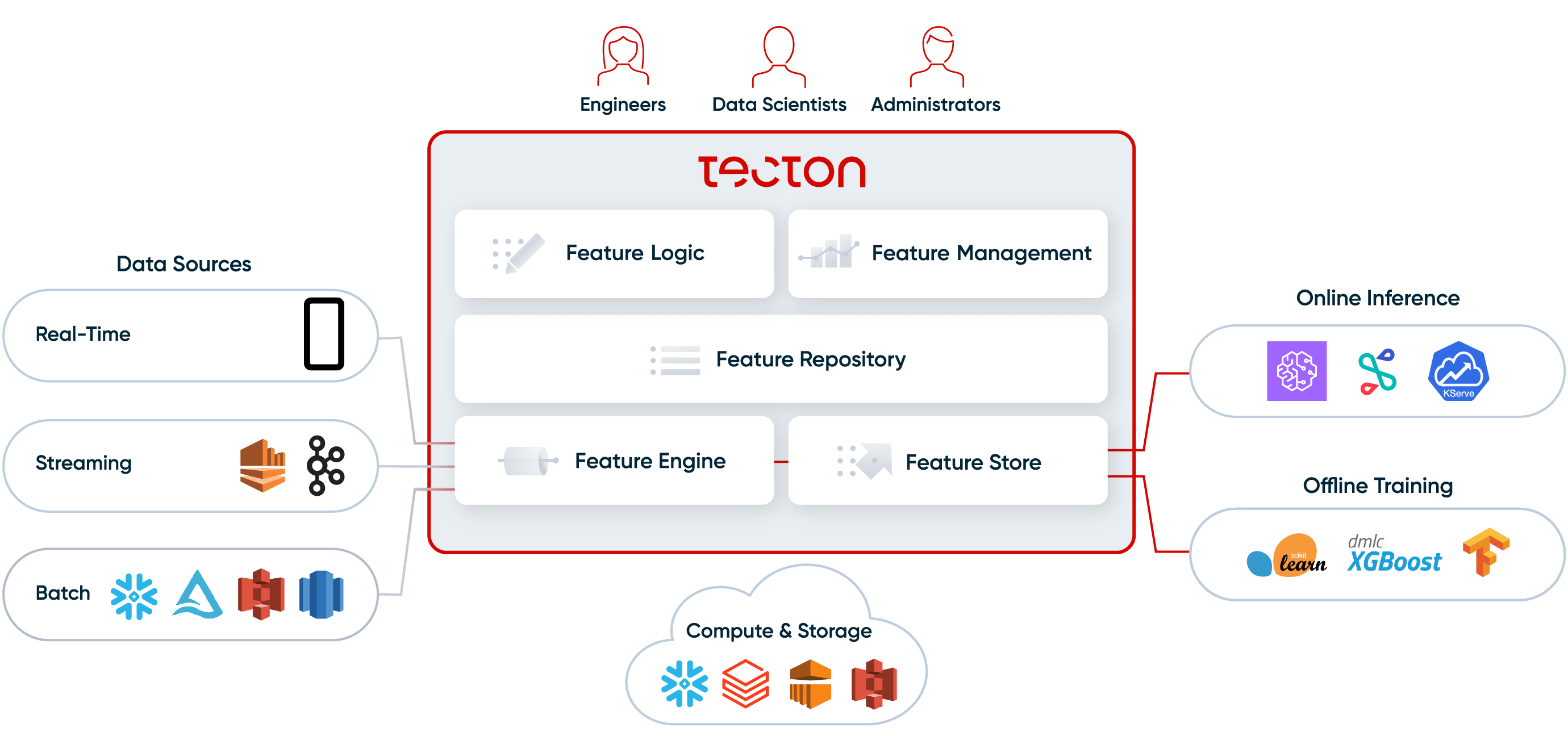
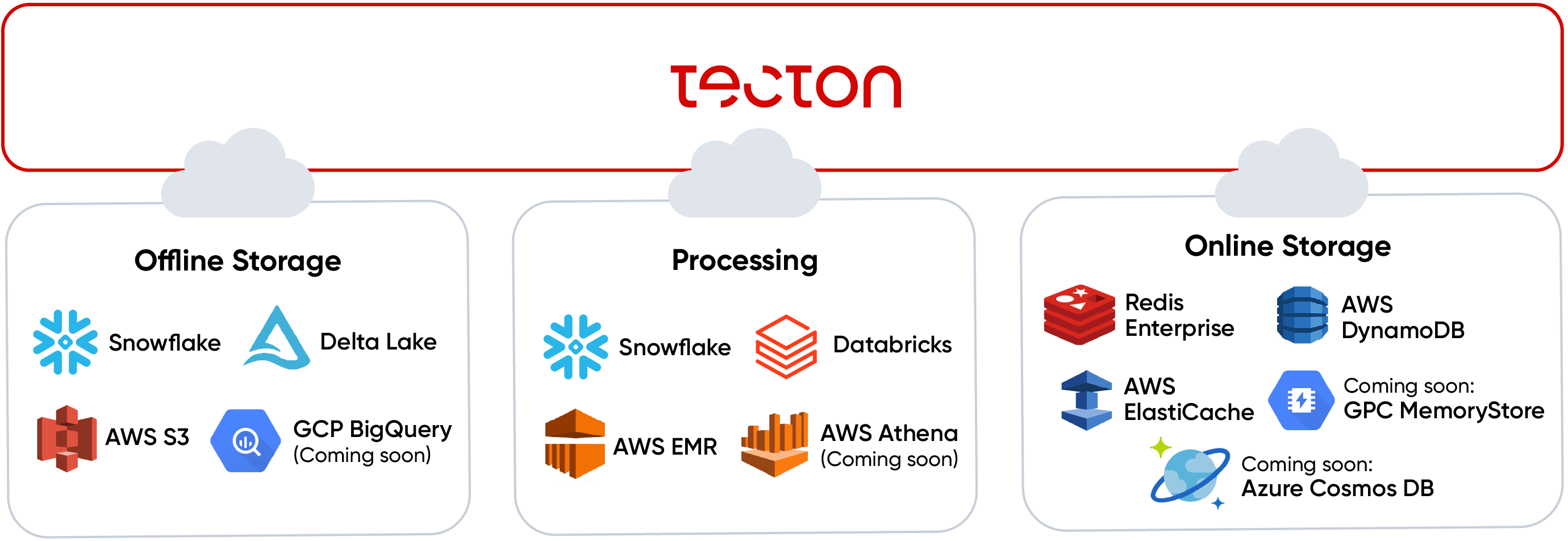
Tecton is also designed to be pluggable with your existing data and ML serving infrastructure; it’s not just another compute or storage system in your stack. Instead, it orchestrates data flows on top of your existing infrastructure. Tecton connects to your existing offline storage (Snowflake, S3, Delta Lake), your existing online storage (AWS DynamoDB, Redis Enterprise, AWS ElastiCache), and your existing processing infrastructure (Snowflake, Databricks, AWS EMR, AWS Athena).
How to choose between Feast and Tecton?
Feast and Tecton are both great products for their respective design points. Choosing the right product comes down to your use cases and your environment, and you need to understand the tradeoffs.
Feast is the better choice if:
- You’re comfortable building and managing your own data pipelines. This can be particularly challenging if you have streaming or real-time transformations or if you have a high velocity of new features that need to be deployed.
- You need the flexibility of an open source solution; for example, if you have extensive requirements for custom integrations.
- You’re comfortable self-deploying and self-managing your feature store.
Tecton is the product we recommend for the majority of users. It’s easier to manage and provides a complete solution to managing the lifecycle of features. Tecton is the better choice if:
- You want to automate batch, streaming, and real-time transformations. Tecton allows ML teams to iterate quickly on production-ready data pipelines.
- You want to enable your team to collaborate on feature definitions using DevOps-like best practices.
- You want to enable ML teams to effectively discover, share, and re-use features.
- You want to monitor data quality and operational service levels.
- You prefer a fully-managed SaaS service to eliminate the overhead of managing your own solution.
Step-by-step comparison of using Feast and Tecton
See demos in: Webinar: Choosing between Feast and Tecton.
Step 1: Create and register features in Feast & Tecton
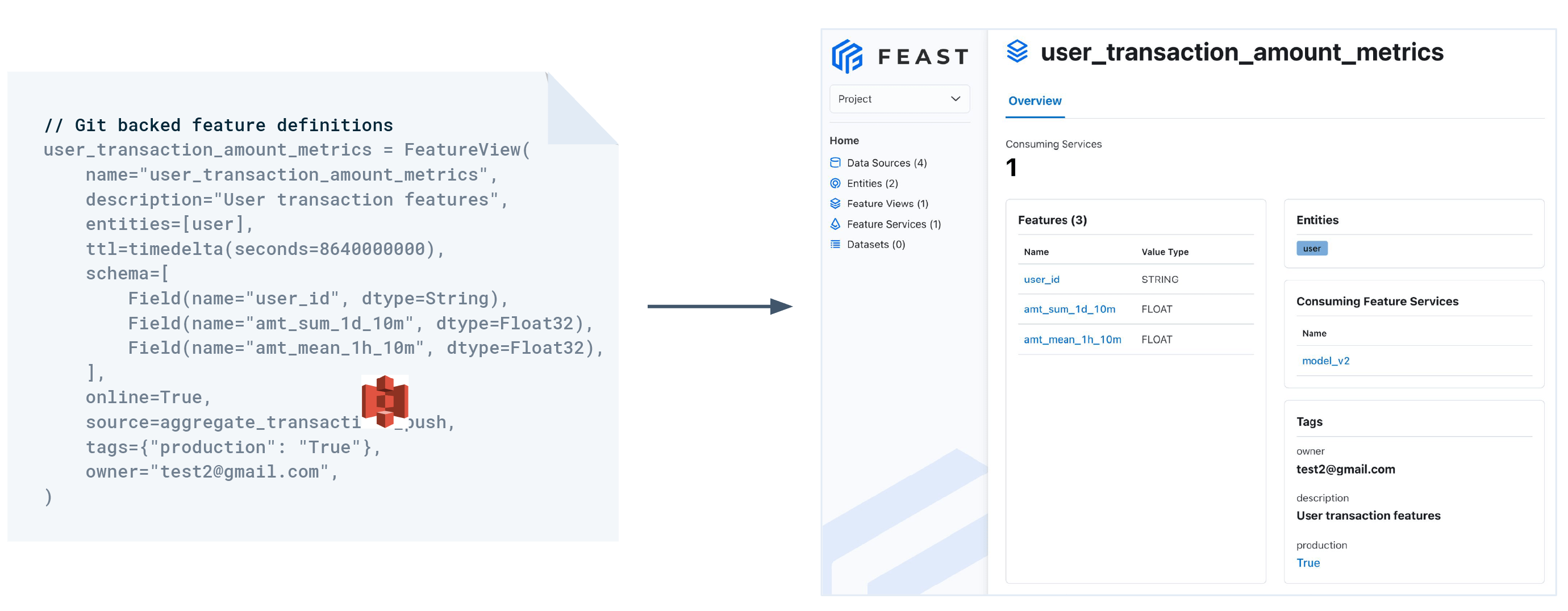
The first step consists in defining and registering features with Feast or Tecton. In Feast, you’ll only register the schemas for features that have already been processed by an upstream pipeline. In Tecton, you’ll register the complete feature definition, which includes the transformation logic.
In Feast…
You bring your own upstream data transformation pipelines. Feast lets you register the schema of the resulting features to power services like the web UI and feature server. Feast defines a framework to help you make already transformed features available for online inference and offline training.
In Tecton….
You provide a complete feature definition, including the transformation logic and configuration data. Using this feature definition, Tecton orchestrates batch, streaming, and real-time data pipelines that compute the desired features from the raw data. Tecton uses your existing compute and storage infrastructure like Databricks and Snowflake to process the features.
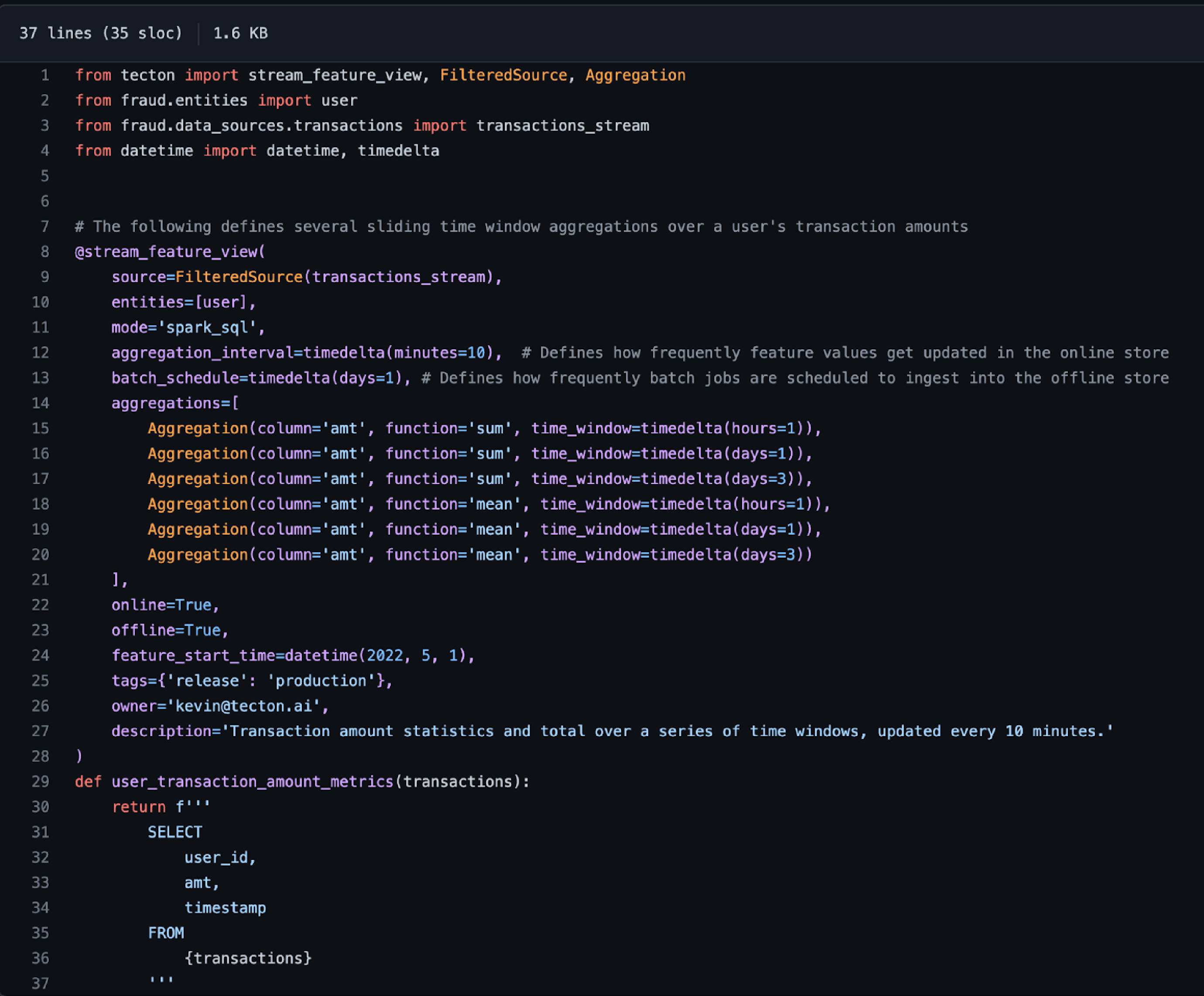
Tecton automates many types of transformations, including:
- Batch transformations:
- Row-level transforms
- Time window aggregations
- Custom aggregations and joins
- Streaming transformations:
- Row-Level transforms
- Time window aggregations
- Real-time / On-Demand transformations::
- Row-level transformations
- Joins across batch and streaming features
After you’ve registered a feature, Tecton manages the lifecycle of that feature. Features are managed in a Git-backed repository, enabling teams to collaborate on feature definitions. Tecton also provides a web UI for effective sharing and re-use of features across models. The UI enables users to search for existing features, track lineage, and explore the data.
Step 2: Create and manage data pipelines
Feast requires that you build and manage your own data transformation pipelines using tools like Airflow. Tecton creates and orchestrates data pipelines to reliably provide fresh feature values to your ML application.
In Feast…
Feast relies on your team to define transformations (e.g., with dbt) and orchestrate pipelines (e.g., with Airflow). Feast provides useful abstractions (feature_store.materialize(…), feature_store.push(…)) so you can orchestrate your pipelines in a unified manner, and decouple data pipelines from ML models.
There are three types of transformations that users have to self-manage when using Feast:
- Streaming feature transformation + ingestion. Feast expects you to reliably produce and push transformed feature values for a feature view (via feature_store.push(…)). Common tools here include Spark Structured Streaming, Flink, and Databricks Jobs.
- Batch feature transformation. Feast expects you to produce transformed features from batch sources. Commonly, users will use tools like Airflow / Argo for orchestration and sometimes dbt to encode a DAG of feature transformations.
- Batch feature ingestion. After transforming batch features, Feast exposes methods to materialize arbitrary time ranges of data into the online store (e.g., via feature_store.materialize(…)). It’s on the user to use the appropriate batch materialization engine to scale materialization and orchestrate these pipelines with tools like Airflow.
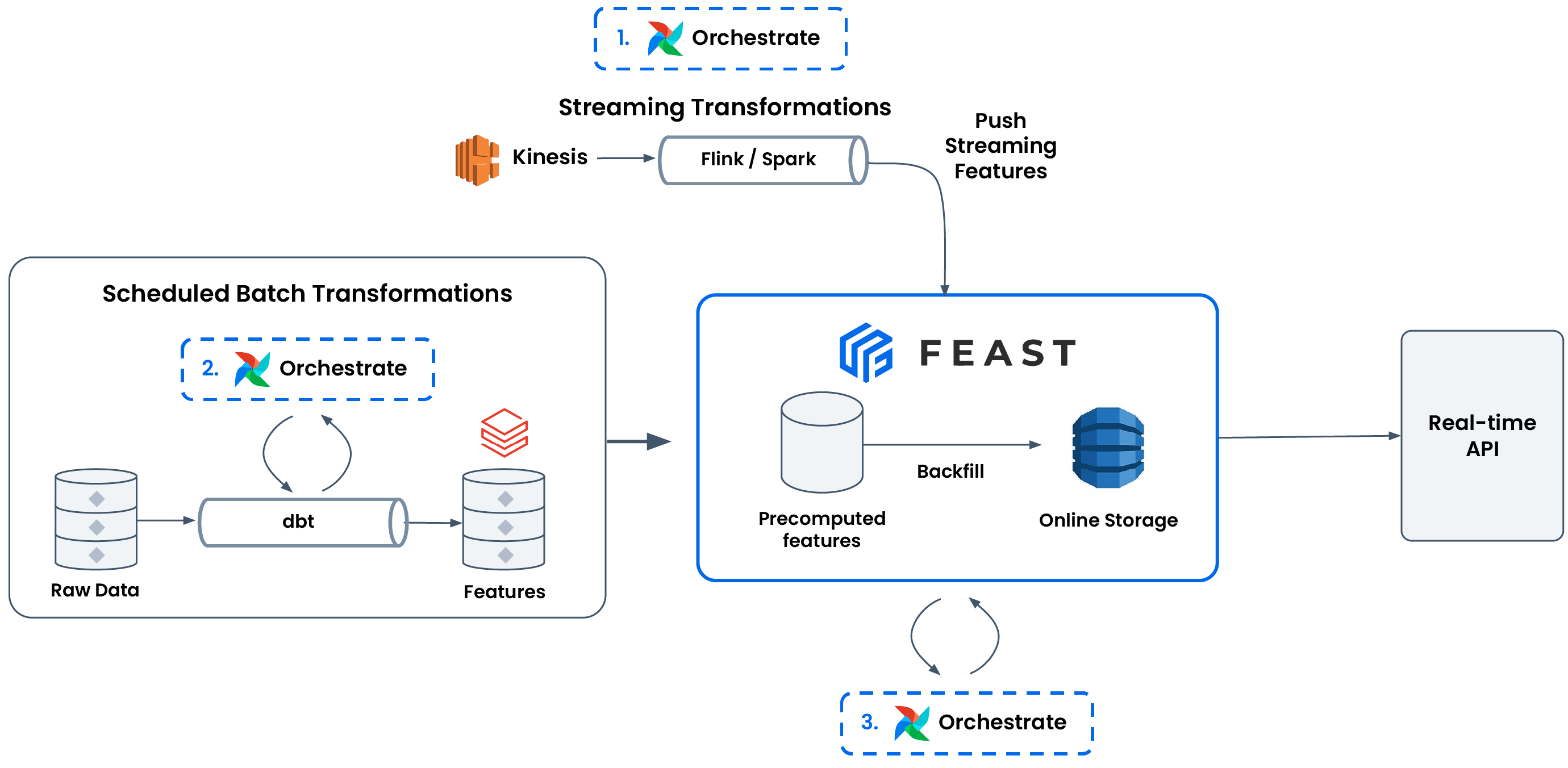
It’s important to have all three because:
- Only having streaming feature ingestion means you are unlikely to have all the feature values you need. You can only generate feature values based on the retention periods of your event queues. You couple this with batch feature transformation and ingestion pipelines to backfill other feature values from historical data.
- Only orchestrating batch feature transformation and not ingestion means you can only access features for training and not for serving.
- Only orchestrating batch feature ingestion and not transformation means you may not have transformed feature values available, leading to missing data in the online store.
Further, it’s critical for a production ML model that all of these pipelines are reliable; otherwise, the model may work with stale / missing feature data and generate incorrect predictions.
In Tecton….
Tecton creates and orchestrates the above types of feature pipelines, resulting in a simpler user experience and production SLAs. Tecton comes out of the box with backfills, job orchestration, retries, monitoring, and alerting. Tecton creates production-ready data pipelines from simple declarative feature definitions.
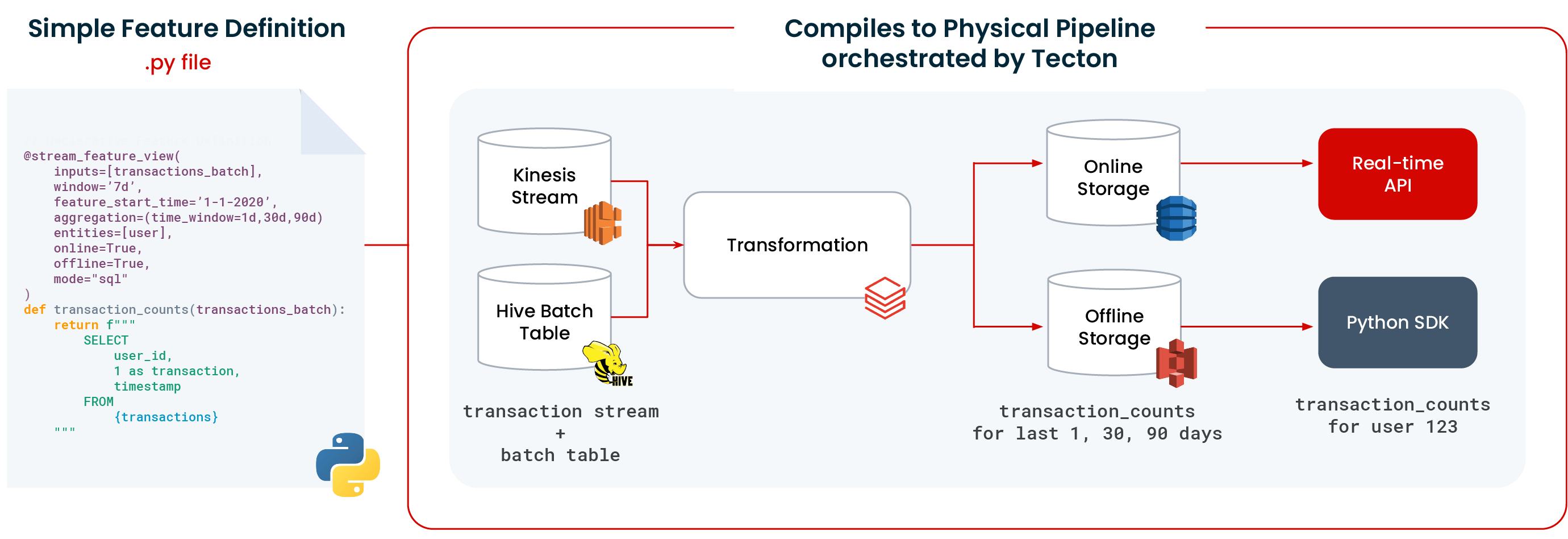
You can have three kinds of feature pipelines in Tecton:
- Fully-managed and orchestrated. In this mode, Tecton is connected to the user’s data source, and manages and executes the full transformation pipelines on your existing compute and storage infrastructure like Snowflake or Databricks. Tecton writes the data into the online and offline store. The feature pipelines run based on a schedule for batch data and continuously for streaming jobs. Tecton provides built-in retries, backoffs, and automated backfills. Users can monitor these jobs for write throughput, freshness, and set up alerting .
- Managed but scheduled by the user. In this mode, materialization jobs can be triggered by an external API as opposed to Tecton managing the materialization schedule. It’s common for users to trigger materialization into Tecton using Airflow or other job orchestration tools. Users can still monitor these jobs with the above metrics and set up alerting.
- Ingestion. In this mode, Tecton is not connected to a user’s data source but provides users with an ingest API which they use to ingest batch data frames at high throughput or to ingest stream records at low latency.
Tecton executes the same transformation pipelines when writing to both online and offline stores, thereby eliminating the skew between training data and serving data. Additionally, in the Python feature definitions, users can define their choice of online / offline stores, along with other parameters to better manage these pipelines.
Batch Pipeline Monitoring
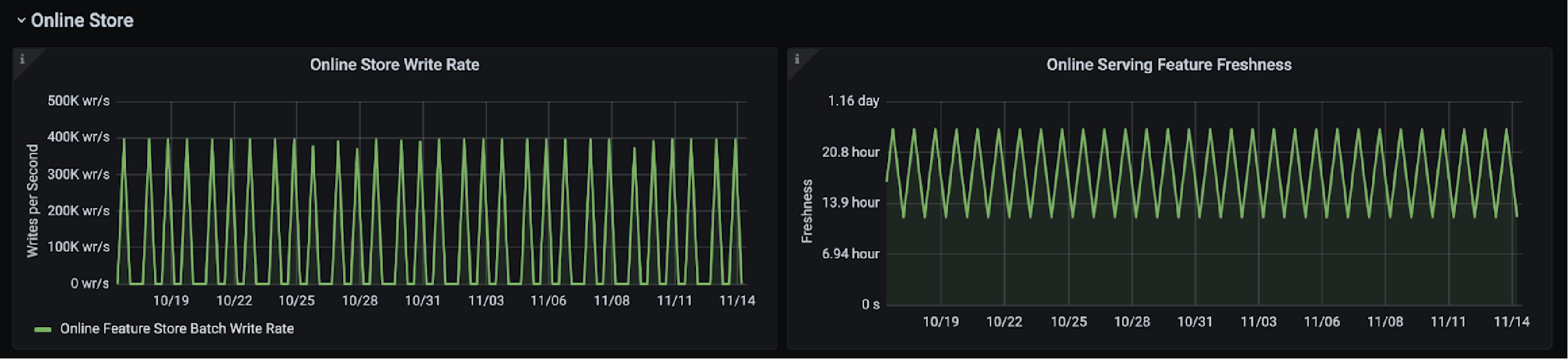
Stream Pipeline Monitoring
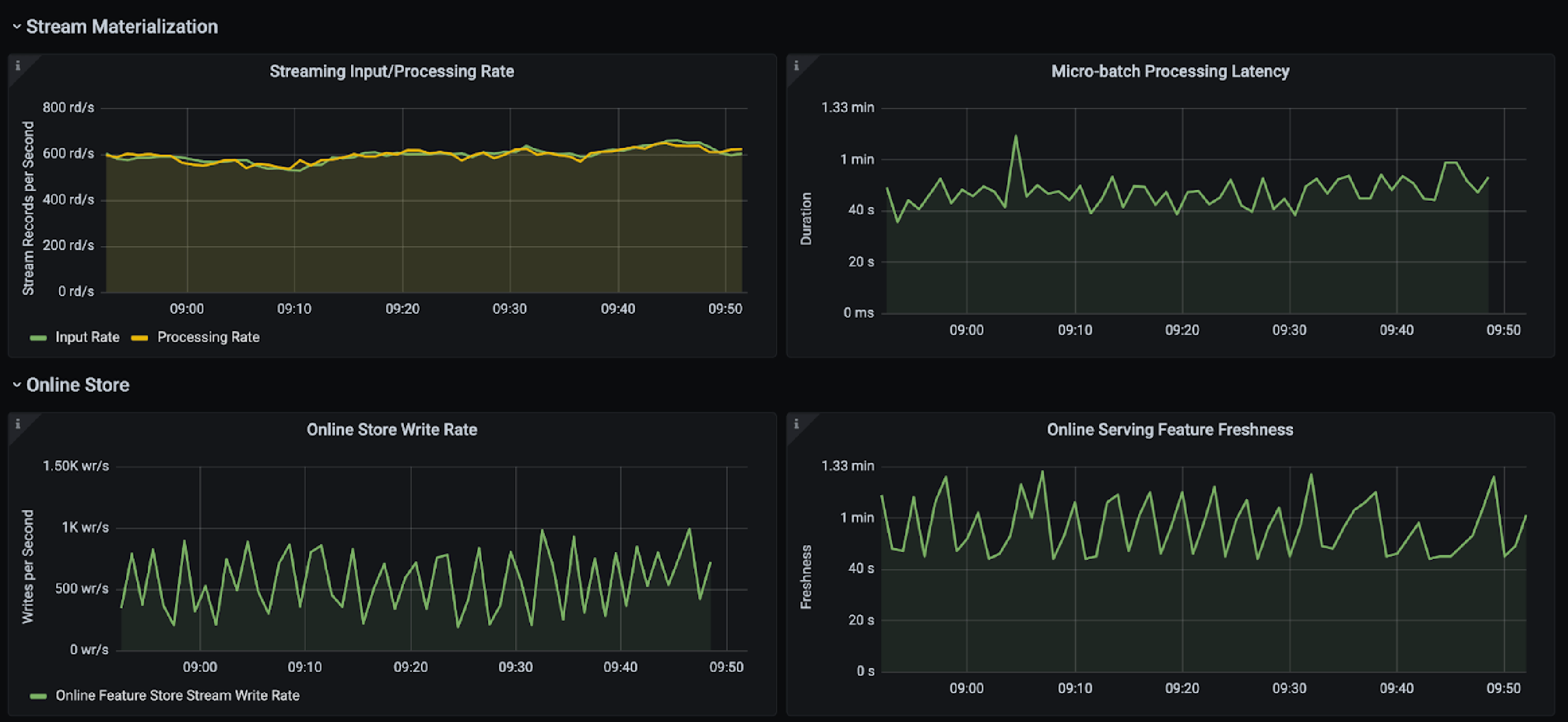
Step 3: Serve features
Both Feast and Tecton provide simple APIs to retrieve features for training and serving. Tecton additionally offers production SLAs behind its battle-tested online serving infrastructure, supports ACLs to restrict data access, and provides client libraries to easily integrate into your services.
In Feast…
Feast provides a consistent and simple API to retrieve features. For training or batch scoring, you call get_historical_features and for online serving, you call get_online_features. Feast will join different groups of features together in a point-in-time correct fashion.
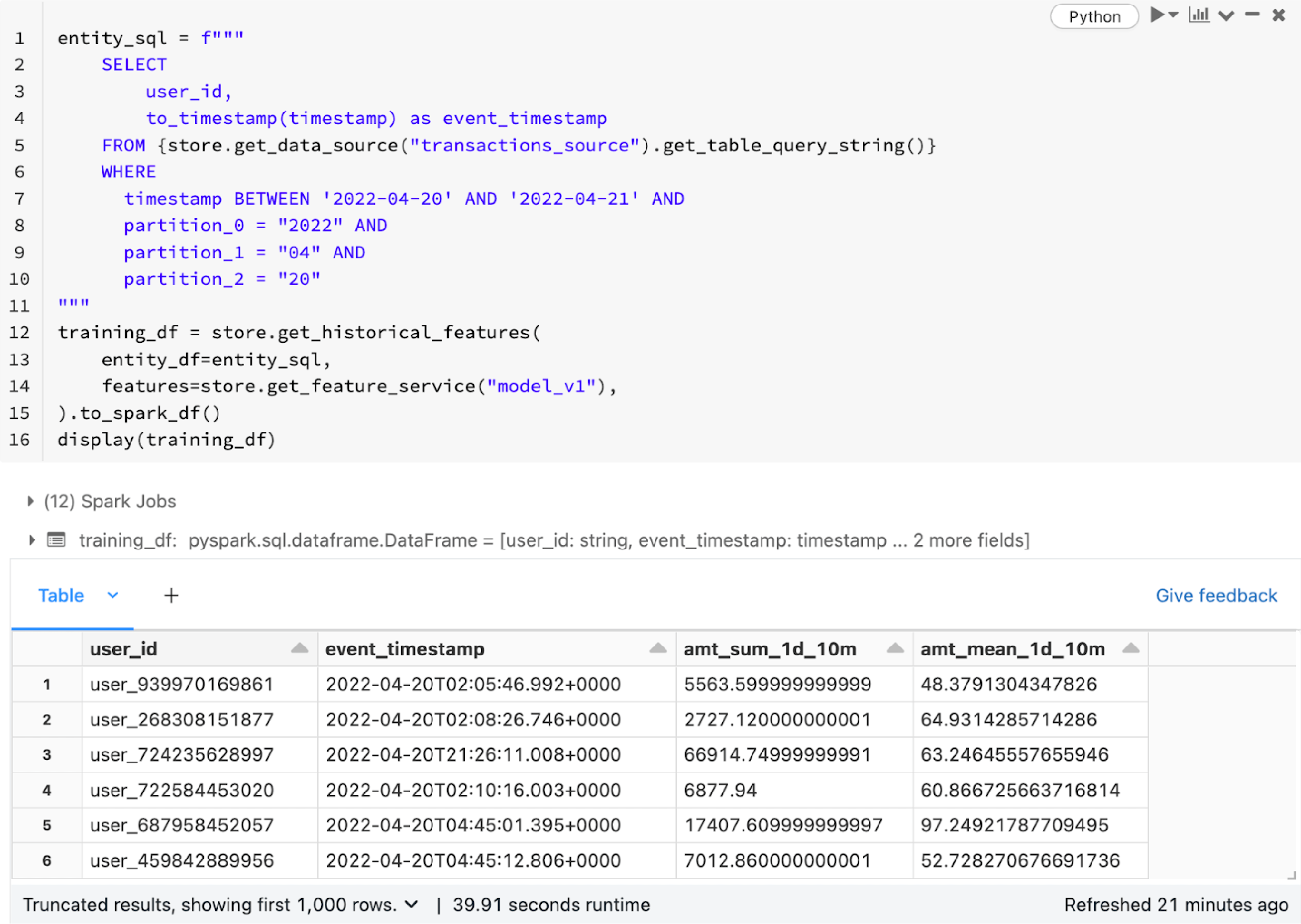
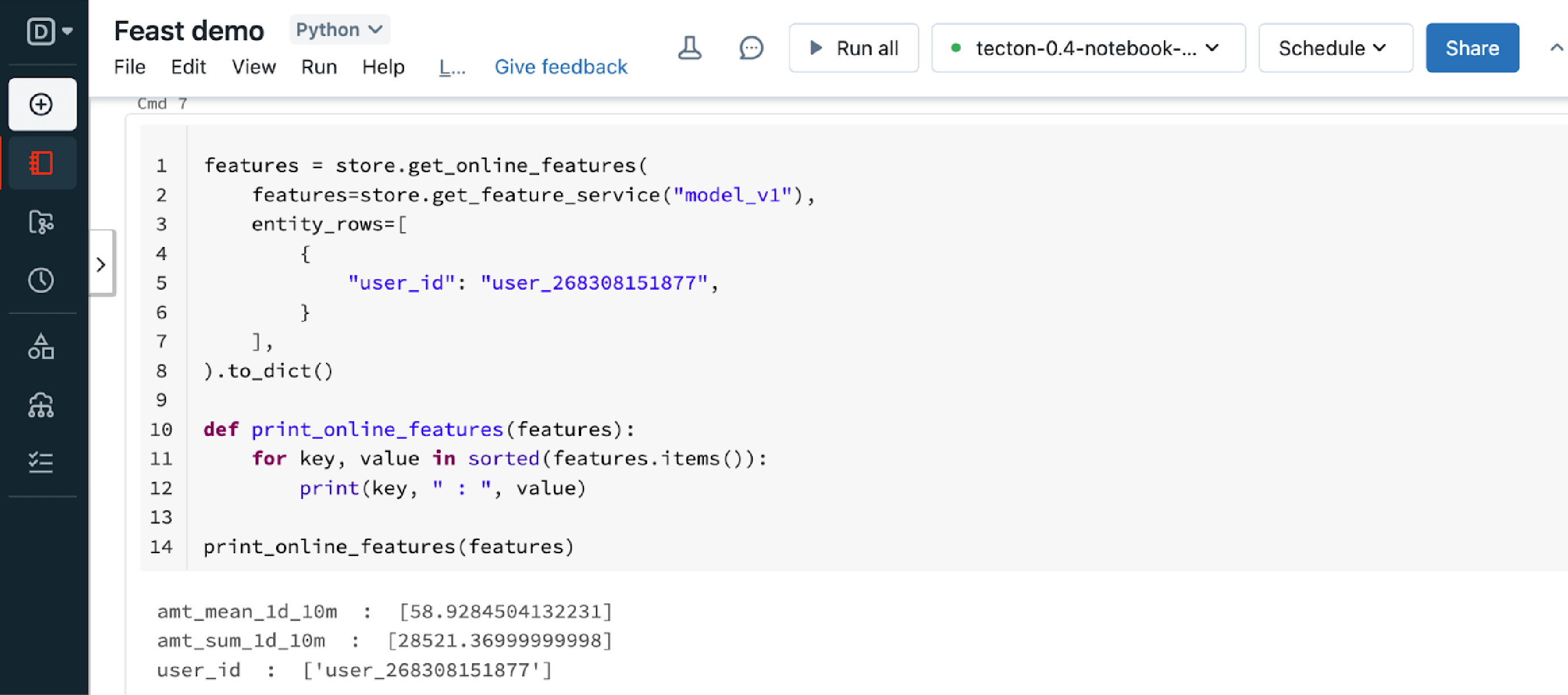
For online inference, Feast provides a Python-based feature server (docs) to expose an HTTP endpoint to retrieve features in real time.
In Tecton….
Similar to Feast, Tecton also provides simple APIs to retrieve features for training and model inference. However, there are two key differences between Tecton and Feast here.
First, Tecton manages online serving so you don’t need to manage or scale up feature serving infrastructure. Tecton provides a low latency HTTP API for feature retrieval, which can serve features at low latency (<10ms) and high throughput (>100,000 QPS) while maintaining high availability. The online serving infrastructure has built in SLAs and monitoring capabilities. Tecton also provides client libraries to make it easier for developers to integrate with Tecton in their production applications.
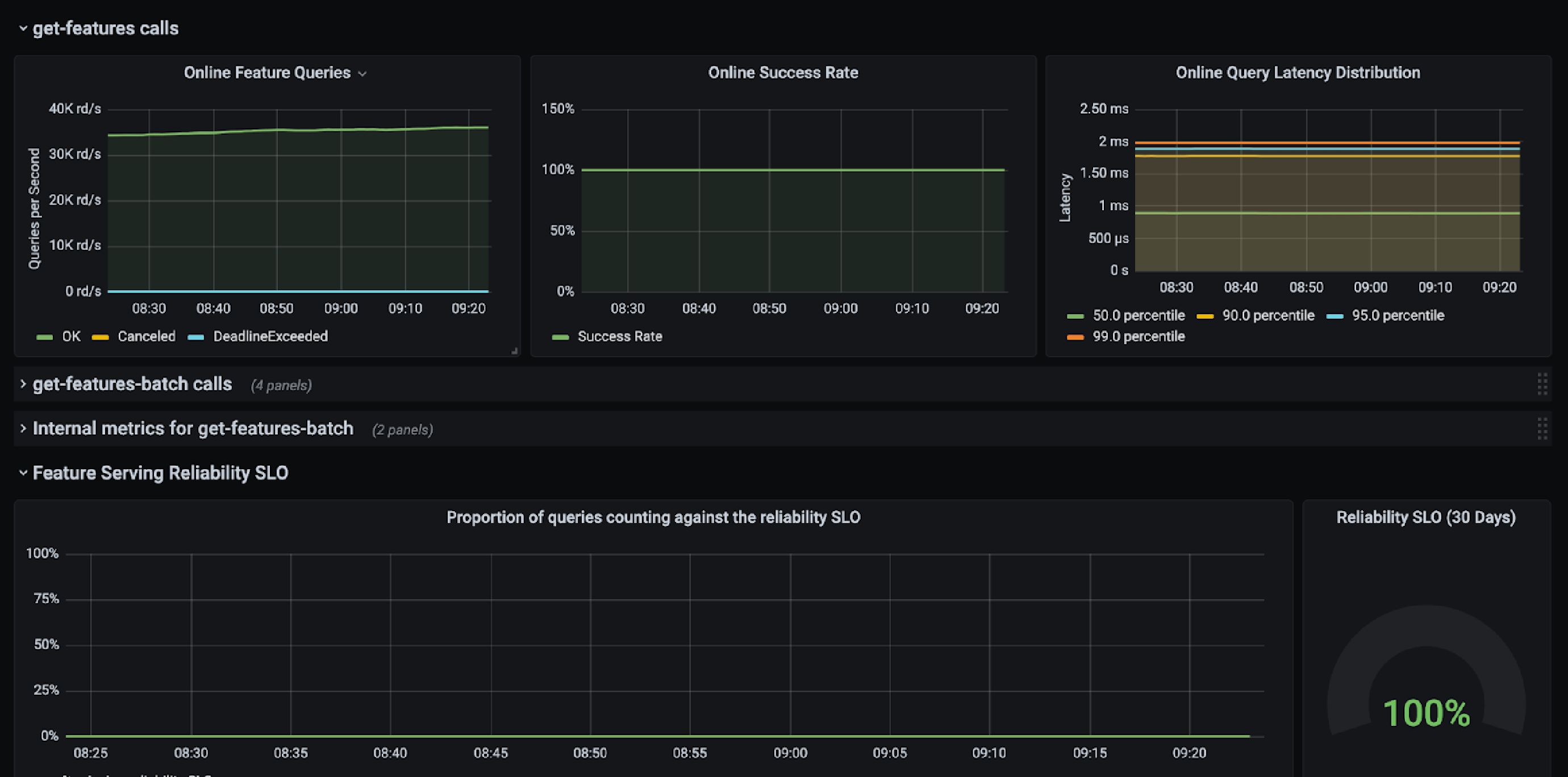
Second, Tecton provides Access Control Lists (ACLs) so only users with specific roles can retrieve data. This is important so that users can’t accidentally break models in production or gain access to sensitive data they shouldn’t have access to.
Step 4: Scale your system
In Feast…
Feast requires custom configuration to power production ML. Feast’s default configuration does not scale to production workloads or meet reliability SLAs. It is the user’s responsibility to design and manage both Feast and non-Feast components to meet production requirements.
A few common challenges and solutions include:
- Challenge: It’s difficult to reliably and scalably compute batch and/or streaming features.
- Potential solution: There are at least 3 parts to addressing this:
- Outside of Feast. Manage data sources (time-partitioning batch data)
- Outside of Feast. Orchestrate and monitor upstream data pipelines (e.g., self-healing batch / streaming pipelines, manage OOMs from streaming aggregations)
- Outside of Feast. Instrument and monitor uptime / latency / freshness metrics with Feast, since Feast does not come with monitoring / metrics.
- Configure, deploy, and manage more scalable / complex implementations of Feast components like a SQL-backed registry or a Bytewax backed batch materialization engine.
- Potential solution: There are at least 3 parts to addressing this:
- Challenge: It’s difficult to scalably and efficiently retrieve features for 100s of candidates in a real-time recommender system.
- Potential solution: Two common steps here are to build a custom Feast online store with a cache and in your application server, managing parallelized requests to fetch features from Feast.
- Challenge: It’s difficult to control the costs of online storage
- Potential solution: Commonly, users will configure expiring feature values in their online store (e.g., with Redis TTLs in Feast), and adding in memory caches in front of the online store
See Running Feast in production for some starting pointers on this!
In Tecton….
Tecton is a fully managed enterprise SaaS service, which automates much of the above complexity. Tecton’s underlying architecture makes it easy to build features at scale with SLA guarantees, and is trusted by sophisticated ML organizations such as Cash App and Roblox.
Recap
Ultimately, Feast is a self-managed feature store that focuses on storing and serving features, whereas Tecton is a fully managed feature platform that also automates feature pipelines and provides production SLAs.
Use Feast if you:
- Have the resources and skills to manage your own feature store
- Need a highly customizable solution
- Don’t need any help with streaming or real-time data pipelines
- Need an air-gapped solution that is deployed in your own datacenter
Use Tecton if you:
- Want minimal overhead in managing your own feature store
- Need mission-critical reliability, scalability, and/or support
- Want to automate batch, streaming, and real-time pipelines
- Want to collaborate on, share, and re-use features
If you’re interested in learning more, we recommend watching the demos available in this recorded webinar: https://resources.tecton.ai/choosing-the-right-feature-store-feast-or-tecton