In today’s data-driven world, organizations are increasingly turning to distributed computing to handle large-scale machine learning workloads. When it comes to feature engineering and retrieval-augmented generation (RAG) systems, the combination of Feast and Ray provides a powerful solution for building scalable, production-ready pipelines.
This blog post explores how Feast’s integration with Ray enables distributed processing for both traditional feature engineering and modern RAG applications, with support for Kubernetes deployment through KubeRay.
The Scaling Challenge
Modern ML teams face critical scaling challenges:
- Massive Datasets: Processing millions of documents for embedding generation
- Complex Transformations: CPU-intensive operations like text processing and feature engineering
- Real-time Requirements: Low-latency retrieval for RAG applications
- Resource Efficiency: Optimal utilization of compute resources across clusters
Building Scalable Feature Pipelines and RAG Systems with Distributed Computing
Feast’s integration with Ray addresses these challenges head-on, providing a unified platform where distributed processing is the default, not an afterthought. The magic happens when you realize that embedding generation, one of the most computationally intensive tasks in modern AI, can be treated as just another transformation in your feature pipeline.
The Ray RAG Revolution
Consider the Ray RAG template, which demonstrates this new approach in action:
# Built-in RAG template with distributed embedding generation
feast init -t ray_rag my_rag_project
cd my_rag_project/feature_repoThis single command gives you a complete system that can process thousands of documents in parallel, generate embeddings using distributed computing, and serve them through a vector database.
The Ray RAG template demonstrates:
- Parallel Embedding Generation: Distribute embedding computation across workers
- Vector Search Integration: Seamless integration with vector databases for similarity search
- Complete RAG Pipeline: Data → Embeddings → Search in one workflow
Embedding Generation as a Feast Transformation
Feast’s Ray integration makes embedding generation a first-class transformation operation. When you define a transformation in Feast, Ray handles the complexity of distributed processing. It partitions your data, distributes the computation across available workers, and manages the orchestration, all transparently to the developer. Here’s how it works in practice:
Distributed Embedding Processing
from feast import BatchFeatureView, Entity, Field, FileSource
from feast.types import Array, Float32, String
from datetime import timedelta
# Embedding processor for distributed Ray processing
class EmbeddingProcessor:
"""Generate embeddings using SentenceTransformer model."""
def __init__(self):
import torch
from sentence_transformers import SentenceTransformer
device = "cuda" if torch.cuda.is_available() else "cpu"
self.model = SentenceTransformer("all-MiniLM-L6-v2", device=device)
def __call__(self, batch):
"""Process batch and generate embeddings."""
descriptions = batch["Description"].fillna("").tolist()
embeddings = self.model.encode(
descriptions,
show_progress_bar=False,
batch_size=128,
normalize_embeddings=True,
convert_to_numpy=True,
)
batch["embedding"] = embeddings.tolist()
return batch
# Ray native UDF for distributed processing
def generate_embeddings_ray_native(ds):
"""Distributed embedding generation using Ray Data."""
max_workers = 8
batch_size = 2500
# Optimize partitioning for available workers
num_blocks = ds.num_blocks()
if num_blocks < max_workers:
ds = ds.repartition(max_workers)
result = ds.map_batches(
EmbeddingProcessor,
batch_format="pandas",
concurrency=max_workers,
batch_size=batch_size,
)
return result
# Feature view with Ray transformation
document_embeddings_view = BatchFeatureView(
name="document_embeddings",
entities=[document],
mode="ray", # Native Ray Dataset mode
ttl=timedelta(days=365 * 100),
schema=[
Field(name="document_id", dtype=String),
Field(name="embedding", dtype=Array(Float32), vector_index=True),
Field(name="movie_name", dtype=String),
Field(name="movie_director", dtype=String),
],
source=movies_source,
udf=generate_embeddings_ray_native,
online=True,
)RAG Query Example
from feast import FeatureStore
from sentence_transformers import SentenceTransformer
# Initialize feature store
store = FeatureStore(repo_path=".")
# Generate query embedding
model = SentenceTransformer("all-MiniLM-L6-v2")
query_embedding = model.encode(["sci-fi movie about space"])[0].tolist()
# Retrieve similar documents
results = store.retrieve_online_documents_v2(
features=[
"document_embeddings:embedding",
"document_embeddings:movie_name",
"document_embeddings:movie_director",
],
query=query_embedding,
top_k=5,
).to_dict()
# Display results
for i in range(len(results["document_id_pk"])):
print(f"{i+1}. {results['movie_name'][i]}")
print(f" Director: {results['movie_director'][i]}")
print(f" Distance: {results['distance'][i]:.3f}")Component Responsibilities
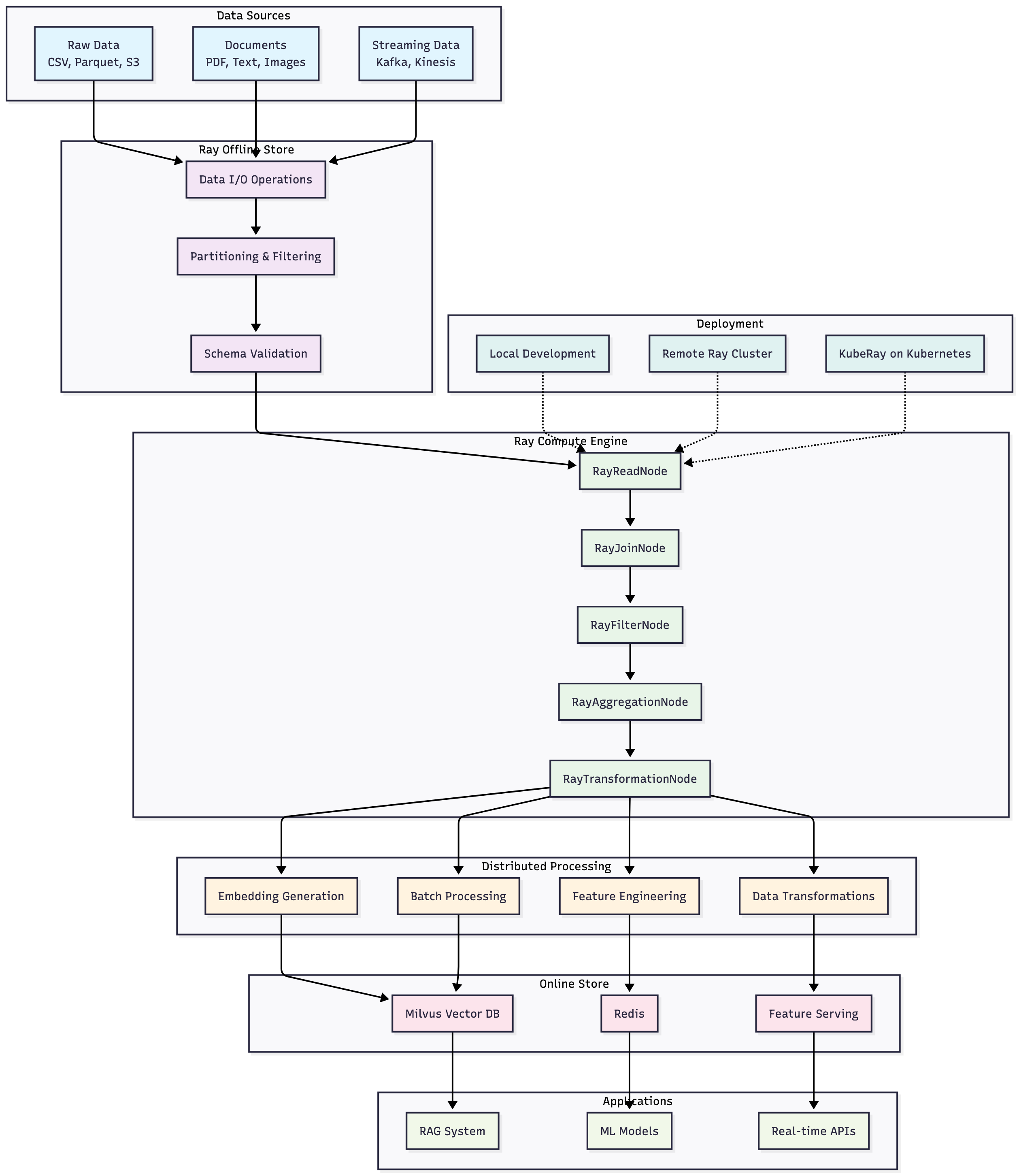
The Feast + Ray integration follows a clear separation of concerns:
- Ray Compute Engine: Executes distributed feature computations, transformations, and joins
- Ray Offline Store: Handles data I/O operations, reading from various sources (Parquet, CSV, etc.)
This architectural separation ensures that each component has a single responsibility, making the system more maintainable and allowing for independent optimization of data access and computation layers.
Ray Integration Modes
Feast supports three execution modes for Ray integration:
1. Local Development
Perfect for experimentation and testing:
offline_store:
type: ray
storage_path: data/ray_storage
# Conservative settings for local development
broadcast_join_threshold_mb: 25
max_parallelism_multiplier: 1
target_partition_size_mb: 162. Remote Ray Cluster
Connect to existing Ray infrastructure:
offline_store:
type: ray
storage_path: s3://my-bucket/feast-data
ray_address: "ray://my-cluster.example.com:10001"3. Kubernetes with KubeRay
Enterprise-ready deployment:
offline_store:
type: ray
storage_path: s3://my-bucket/feast-data
use_kuberay: true
kuberay_conf:
cluster_name: "feast-ray-cluster"
namespace: "feast-system"Getting Started
Install Feast with Ray Support
pip install feast[ray]Initialize Ray RAG Template
# RAG applications with distributed embedding generation
feast init -t ray_rag my_rag_project
cd my_rag_project/feature_repoDeploy to Production
feast apply
feast materialize --disable-event-timestamp
python test_workflow.pyWhether you’re building traditional feature pipelines or modern RAG systems, Feast + Ray offers the scalability and performance needed for production workloads. The integration supports everything from local development to large-scale Kubernetes deployments, making it an ideal choice for organizations looking to scale their ML infrastructure.
Ready to build distributed RAG applications? Get started with our Ray RAG template and explore Feast + Ray documentation for distributed embedding generation.
Learn more about Feast’s distributed processing capabilities and join the community at feast.dev.